
2022년 8월 동안 검색하고 공부한 것들을 정리한 내용입니다.
1. 다른 길이의 리스트를 컬럼으로 split
사용된 데이터는 다음과 같이 서로 다른 길이의 list가 기록된 dataframe을 이용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
import pandas as pd
arr1 = [
['a', 'a,b,c'],
['b', 'a,b'],
['c', 'a,b,c,d'],
['d', 'a']
]
arr1
df = pd.DataFrame(data=arr1, columns=['index','value'])
df

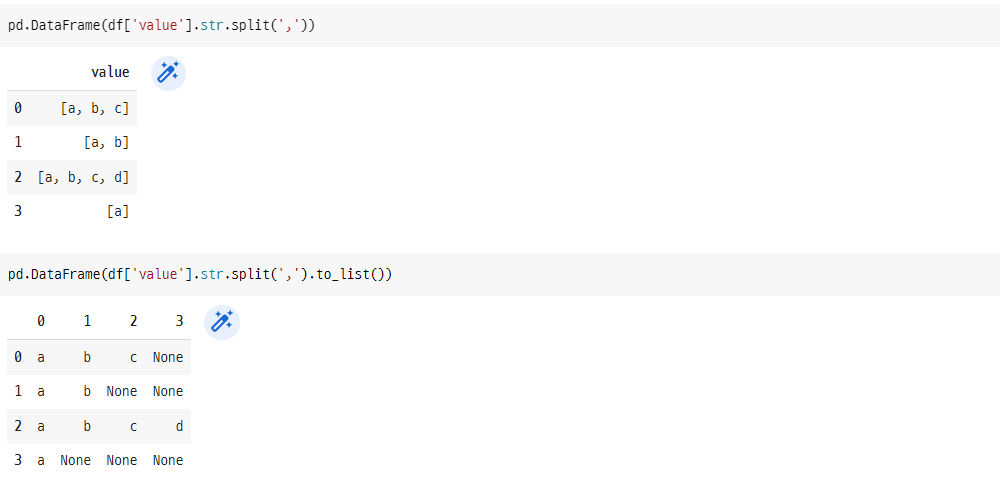
split 함수를 통해 리스트의 값들을 분리한 뒤 to_list 함수를 이용해 리스트로 한번 더 감싸줘야 제대로 된 결과를 얻을 수 있습니다.
1
2
3
pd.DataFrame(df['value'].str.split(','))
pd.DataFrame(df['value'].str.split(',').to_list())
2. np.select
np.select 함수를 이용하면 ‘여러 가지 조건에 따라 서로 다른 (연산의) 값을 추출할 수 있습니다. 참고로, 조건이 하나인 경우는 np.where를 이용하고 조건이 여러 개이고 각각 다른 출력을 원한다면 np.select를 이용하는게 편하다고 생각합니다.
numpy.select(condlist, choicelist, default=0)
Return an array drawn from elements in choicelist, depending on conditions.
아래와 같이 ‘x<3’인 경우는 x를 그대로 뽑고, ‘x>3’인 경우 x의 제곱을 뽑도록 할 수 있습니다. 또한, default 옵션을 통해 어떤 조건도 만족하지 않는 경우 어떤 값을 가질 것인지를 지정할 수 있습니다.
1
2
3
4
5
6
7
import numpy as np
x = np.arange(6)
condlist = [x<3, x>3]
choicelist = [x, x**2]
np.select(condlist, choicelist, default = 42)
# array([ 0, 1, 2, 42, 16, 25])
3. np.stack
np.stack 함수를 이용하면 array들을 필요한 axis에 따라 합칠 수 있습니다.
numpy.stack(arrays, axis=0, out=None)
Join a sequence of arrays along a new axis.
1
2
3
4
5
6
7
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
np.stack((a, b),axis=0)
np.stack((a, b),axis=1)

3.1 np.hstack & np.hsplit
np.hstack 함수를 이용하면 column-wise하게(2번째 axis에 따라) concat한 array를 계산할 수 있습니다. 단, 1-D array의 경우는 1번째 axis에 따라 concat하여 계산됩니다.
또한, np.hsplit 함수는 np.hstack의 정반대 기능을 합니다.
1
2
3
4
5
6
7
np.hstack((a,b))
print(a.shape)
print(np.hstack((a,b)).shape)
np.hsplit(np.hstack((a,b)),2)
np.hsplit(np.hstack((a,b)),3)

이외에도 np.vstack, np.dstack 등 어떤 axis에 대해서 concat하는지에 따라 다양한 함수들이 있습니다.
4. f-string with formatting
파이썬의 f-string을 이용할 때, 포맷도 같이 지정하고 싶은 경우가 있습니다. 이럴 때는 ‘변수:포맷’의 형태를 이용하면 됩니다. 해당 형식은 f-string 뿐 아니라 format 함수에서 포맷을 지정하는 형식과 동일합니다.
1
2
3
4
num = 57892359
print(f"num : {num}") # num : 57892359
print(f"num : {num:,}") # num : 57,892,359
print(f"num : {num:,.2f}") # num : 57,892,359.00
5. pd.MuliIndex.droplevel
pandas 공식문서 - droplevel
pandas 공식문서 - swaplevel
pd.MuliIndex.droplevel 함수를 이용해 멀티인덱스 컬럼의 특정 레벨을 삭제할 수 있습니다.
MultiIndex.droplevel(level=0)
Return index with requested level(s) removed.
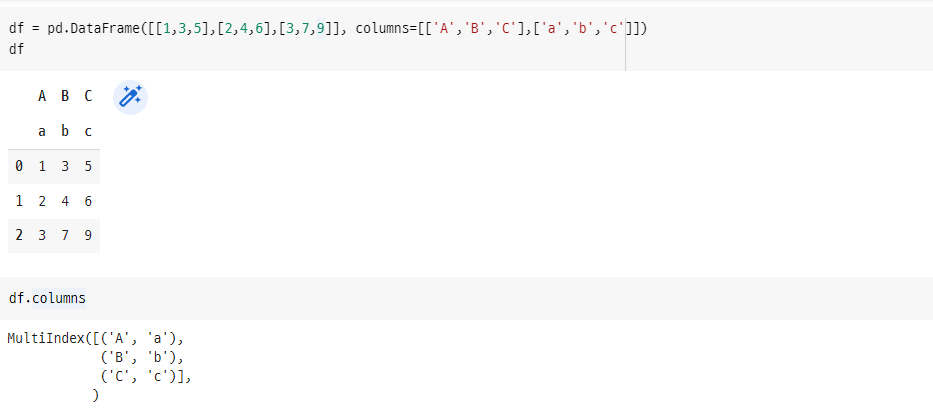
먼저, 아래와 같이 2개의 레벨을 가지는 멀티인덱스 컬럼의 데이터프레임을 생성합니다.
1
2
3
4
5
6
import pandas as pd
df = pd.DataFrame([[1,3,5],[2,4,6],[3,7,9]], columns=[['A','B','C'],['a','b','c']])
df
df.columns
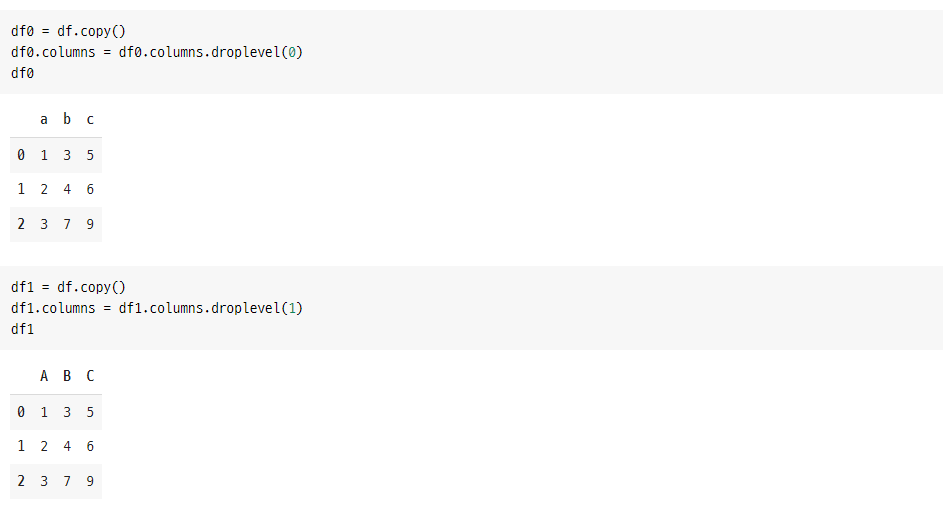
MultiIndex.droplevel 함수를 이용해 삭제하고 싶은 레벨을 지정할 수 있습니다.
1
2
3
4
5
6
7
df0 = df.copy()
df0.columns = df0.columns.droplevel(0)
df0
df1 = df.copy()
df1.columns = df1.columns.droplevel(1)
df1
MultiIndex.swaplevel 함수를 이용하면 지정한 레벨의 인덱스들을 서로 바꿀 수 있습니다.
1
df.columns.swaplevel(0,1)
