
numpy array의 각 행(또는 열)의 값이 모두 같은지를 확인하는 코드를 chatGPT를 통해 알아본 적이 있습니다. 답변을 얻기 위한 과정과 이 과정 중 인사이트를 얻은 경험에 대해 알아 보겠습니다.
TL;DR
- numpy array의 각 행(또는 열)의 값이 모두 같은지를 확인하는 방법 2가지.
[np.all(X[i] == X[i][0]) for i in range(len(X))][len(set(X[i])) == 1 for i in range(len(X))]
np.all은 vectorized 연산,set은 python loop 연산.- 일반적인 상황에서는
np.all을 이용한 경우가 더 빠르게 연산.
1. GPT 3.5
이전 질문들을 통해 numpy array의 각 행의 값이 모두 같은지를 확인하는 2가지 방법을 확인했습니다. 하나는 np.all을 이용해 해당 행의 값이 첫 값과 동일한지 확인하는 방법이었고, 나머지는 set(np.array)의 길이가 1인지 확인하는 방법입니다. 추가적으로 2가지 방법 중 어떤 방법이 빠른지 확인했고, np.all을 이용한 방법이 더 빠를 것이라는 답변을 확인했습니다. 그에 대한 내용은 아래와 같습니다.
Q. 2가지 방법 - 하나는 array에 대한 set의 길이 확인, 나머지 하나는 모든 행의 값 비교 - 중 더 빠른 방법은?
A. np.all()을 이용한 방법이 set(array)의 길이를 비교하는 방법보다 빠를 것. 왜냐하면 np.all()은 vectorized 연산을 통한 element-wise 비교이고, 이 방법은 large arrays 연산에 최적화되어 있음.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import numpy as np
import timeit
X = np.array([[0, 1], ['a', 'a']])
def check_elements_equal(X):
return [np.all(X[i] == X[i][0]) for i in range(len(X))]
def check_elements_equal_set(X):
return [len(set(X[i])) == 1 for i in range(len(X))]
# Measure the time for the first approach
time1 = timeit.timeit(lambda: check_elements_equal(X), number=10000)
# Measure the time for the second approach
time2 = timeit.timeit(lambda: check_elements_equal_set(X), number=10000)
print("Time for using np.all():", time1)
print("Time for using set():", time2)
# Time for using np.all(): 0.02474087499999478
# Time for using set(): 0.03572764500002132
chatGPT의 답이 정확한지 확인하기 위해 로컬 환경에서 확인을 추가로 했고 답변과 다른 결과를 확인했습니다. 결과는 아래와 같이 set을 이용한 방법이 더 빨랐습니다.
1
2
3
4
print("Time for using np.all():", time1)
print("Time for using set():", time2)
# Time for using np.all(): 0.28116859899999724
# Time for using set(): 0.09155996799999855
chatGPT는 “생성형”이 목적이므로 코드 실행 결과와 같은 답변은 실제와 다를 수 있을 것이라 생각했습니다. 그러면서도 답변을 다시 읽어보았고 “large arrays에 최적화”라는 키워드를 질문에 활용해 결과를 다시 확인했습니다.
2. Code Interpreter
chatGPT의 code interpreter는 질문에 대해 array 길이에 따른 2가지 방법의 성능 비교를 위해 간단한 실험을 구성하고 결과를 그래프로 시각화해 보여주었습니다. 질문과 답변은 아래와 같습니다.
Q. 2가지 방법 - 하나는 array에 대한 set의 길이 확인, 나머지 하나는 모든 행의 값 비교 - 중 array 길이가 긴 상황 등 다양한 조건에서 일반적으로 더 빠른 방법은?
A. 실험을 진행한 결과np.all을 이용한 경우가 빠르다. numpy 함수는 vectorized 연산에 대해 최적화되어 있어 large array에 대한 연산에 유리하고, set 함수는 python loop를 이용해 large array에 대한 연산에 불리하므로 실험과 같은 결과가 나왔다.
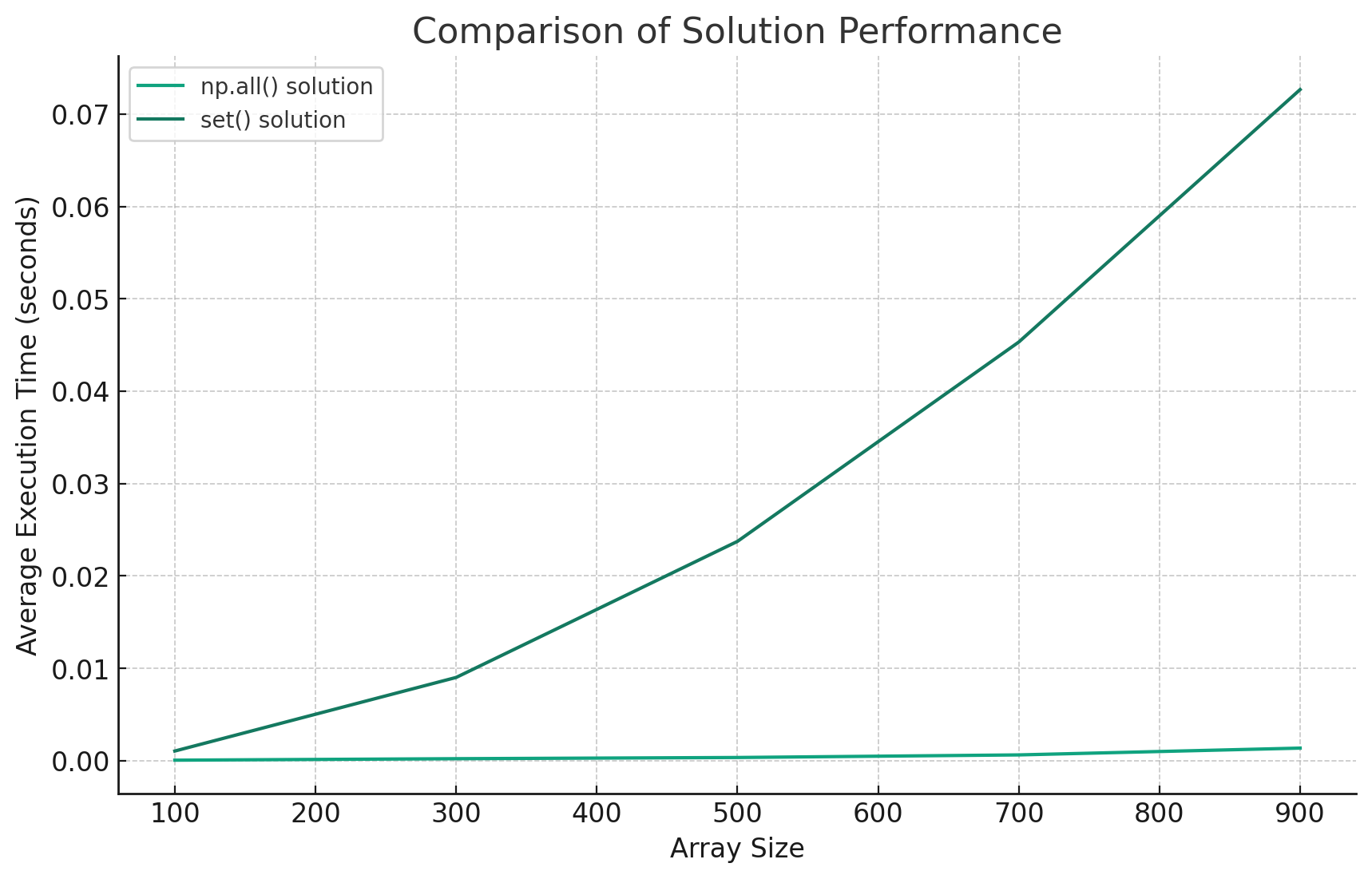 Array 길이에 따른 평균 코드 실행 시간 created by chatGPT code interpreter.
Array 길이에 따른 평균 코드 실행 시간 created by chatGPT code interpreter.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import numpy as np
import timeit
# Define the two solution functions
def solution_np_all(array):
return np.all(array == array[:,0].reshape(-1,1), axis=1)
def solution_set(array):
return [len(set(row)) == 1 for row in array]
# Define the experiment function
def run_experiment(min_size, max_size, step_size, num_trials):
np_all_times = []
set_times = []
sizes = list(range(min_size, max_size, step_size))
for size in sizes:
np.random.seed(42)
array = np.random.randint(0, 2, size=(size, size))
np_all_start_time = timeit.default_timer()
for _ in range(num_trials):
solution_np_all(array)
np_all_end_time = timeit.default_timer()
np_all_times.append((np_all_end_time - np_all_start_time) / num_trials)
set_start_time = timeit.default_timer()
for _ in range(num_trials):
solution_set(array)
set_end_time = timeit.default_timer()
set_times.append((set_end_time - set_start_time) / num_trials)
return sizes, np_all_times, set_times
# Run the experiment
sizes, np_all_times, set_times = run_experiment(min_size=100, max_size=1100, step_size=200, num_trials=10)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(sizes, np_all_times, label='np.all() solution')
plt.plot(sizes, set_times, label='set() solution')
plt.xlabel('Array Size')
plt.ylabel('Average Execution Time (seconds)')
plt.title('Comparison of Solution Performance')
plt.legend()
plt.grid(True)
plt.show()
3. 마무리
code interpreter의 코드를 기반으로 확인했을 때, (일반적으로) array의 길이가 4 이상일 경우부터 set(array)를 이용한 결과의 성능이 더 느리게 나왔습니다. 다시 로컬에서 확인했던 결과를 보면 해당 경우는 array 길이가 크지 않았기에 set(array)을 이용한 경우가 더 빠르게 나온 것으로 생각되며, 일반적인 상황에서는 np.all을 이용한 경우가 더 빠르게 연산을 할 것이라 생각됩니다.