
많은 경우에 수집된 데이터가 그대로 데이터 분석에 사용되지 않습니다. 사용하는 방법론에 따라, 분석 대상에 따라, 이외 여러 가지의 이유로 데이터를 변환하는 작업을 합니다. 이런 데이터 핸들링에 도움이 되는 python 함수들을 알아보고자 합니다.
enumerate
- enumerate(*args, **kwargs)
- 예시) 반복문에서 순서와 값이 모두 필요할 때 사용.
1
2
3
4
5
6
7
8
a = ['apple','banana','cat','dog']
for index, element in enumerate(a) :
print(f"({index} : {element})")
# (0 : apple)
# (1 : banana)
# (2 : cat)
# (3 : dog)
zip
- zip(*iterables)
- 예시) 쌍(pair)으로 반복(iterate)할 때 사용.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
a = [i for i in range(10)]
b = [j for j in range(1,11)]
print(f"a : {a}") # a : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(f"b : {b}") # b : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for i, j in zip(a,b) :
print(f"({i},{j})")
# (0,1)
# (1,2)
# (2,3)
# (3,4)
# (4,5)
# (5,6)
# (6,7)
# (7,8)
# (8,9)
# (9,10)
map
- map(func, *iterables)
- 예시) 반복해서 함수를 적용할 때 사용.
1
2
3
4
5
def square_root(x) : return(x**(1/2))
c = [1,2,4,9,16]
print(list(map(square_root,c)))
# [1.0, 1.4142135623730951, 2.0, 3.0, 4.0]
crosstab
- def crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None,…)
- 예시) 간단한 cross-table을 만들 때 사용.
- Parameters
- margins: bool, default False. row/column에 대한 subtotal을 제공.
- margins_name: str, default ‘All’
normalize: bool, {‘all’, ‘index’, ‘columns’}, or {0,1}, default False. 조건에 따라 normalize한 값을 제공.
- ‘all’ or True : 모든 값에 대해서 normalize.
- ‘index’ : 각 행별로 normalize.
- ‘columns’ : 각 열별로 normalize.
1
2
3
4
5
import pandas as pd
import seaborn as sns
mpg = sns.load_dataset('mpg')
mpg.head()
1
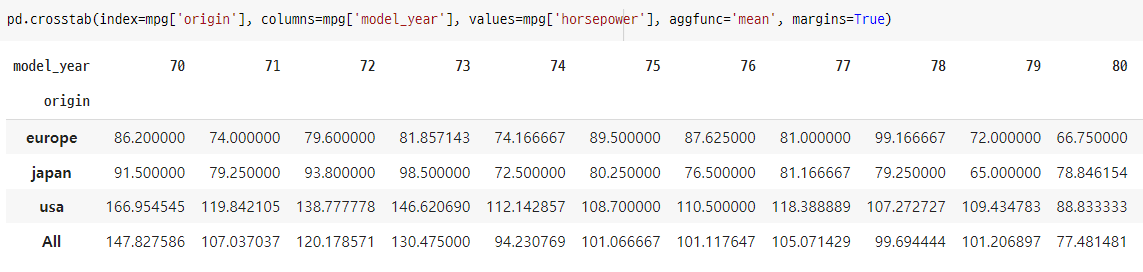
pd.crosstab(index=mpg['origin'], columns=mpg['model_year'], values=mpg['horsepower'], aggfunc='mean', margins=True)
cut
- def cut(x, bins, right: bool=True, labels=None, retbins: bool=False, …)
- 예시) 연속형 값을 이산화/구간화할 때 사용.
- Parameters
- x : array-like. 1차 array여야 함.
bins : int, sequence of scalars, or IntervalIndex.
- int : 동일한 길이의 구간 생성.
- sequence of scalars : 구간의 길이가 동일하지 않을 수 있음.
- IntervalIndex : 비연속적인 구간 설정 가능.
- right : bool, default True. 오른쪽 경계값의 포함 여부.
- labels : array or False, default None. 각 bins의 label 부여.
- retbins : bool, default False. bins에 대한 정보.
- include_lowest : bool, default False
1
2
3
4
5
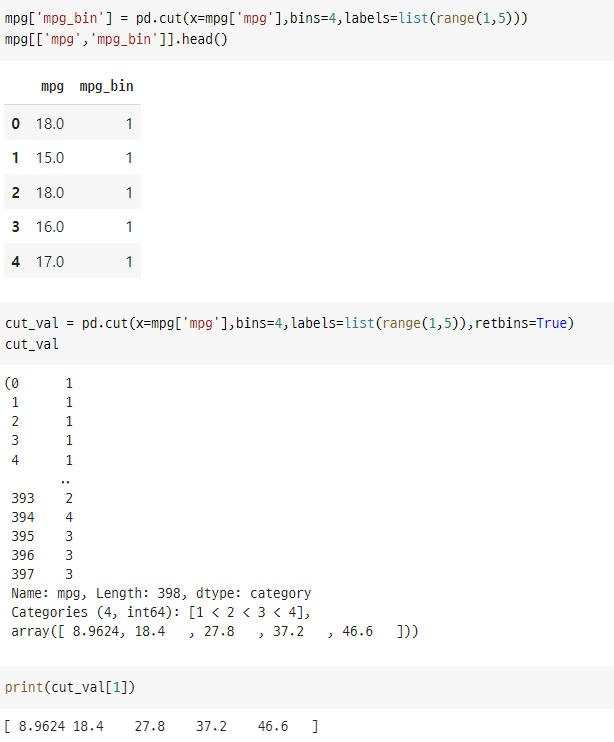
mpg['mpg_bin'] = pd.cut(x=mpg['mpg'],bins=4,labels=list(range(1,5)))
mpg[['mpg','mpg_bin']].head()
cut_val = pd.cut(x=mpg['mpg'],bins=4,labels=list(range(1,5)),retbins=True) # retbins : return the bins.
cut_val
qcut
- def qcut(x, q, labels=None, retbins: bool=False, …)
- 예시) 특정 분위수(quantile)에 대해서 구간화할 때 사용.
- Parameters
- x : 1d ndarray or Series
- q : int or list-like of float. 분위수의 개수 또는 지정하고자 하는 분위수의 list.
1
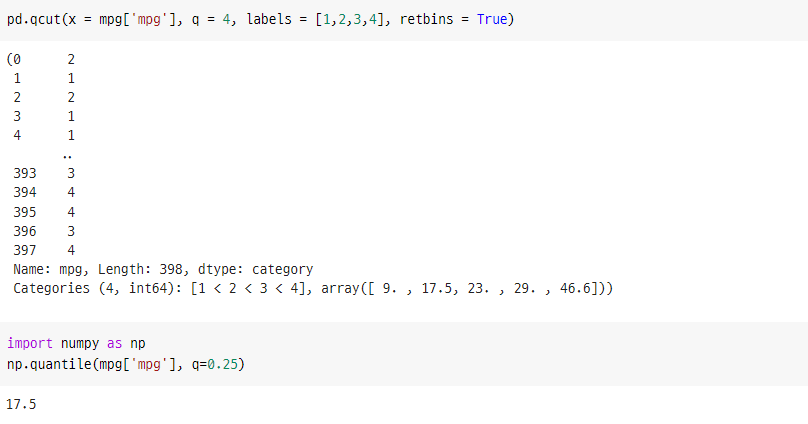
pd.qcut(x = mpg['mpg'], q = 4, labels = [1,2,3,4], retbins = True)
select_dtypes
- def select_dtypes(include=None, exclude=None)
- 예시) 필요한 type의 변수만 이용하고자 할 때 사용.
- parameters
- include, exclude : scalar or list-like
1
2
mpg.select_dtypes(include='object').head()
mpg.select_dtypes(exclude='object').head()
idxmin / idxmax
- def idxmin(axis=0, skipna=True, *args, **kwargs)
- 예시) 최소값(idxmin) 혹은 최대값(idxmax)의 row 위치를 알고자 할 때 사용.
- 찾고자 하는 값이 unique하지 않다면 가장 처음 나오는 row 위치를 알려줌.
- parameters
- axis : int, default 0
- skipna : bool, default True
1
2
3
4
5
6
7
8
9
10
11
12
13
import pandas as pd
x=pd.Series([3,1,2,6,4,9,1,5,9])
print(x.idxmin())
print(x.idxmax())
# 1
# 5
df = pd.DataFrame()
df['X'] = [0,0,0,0,3,1,2,6,9,5,1,9]
df['X'].ne(0).idxmax()
# 4
nsmallest & nlargest
- def nsmallest(n, columns, keep=’first’)
- 예시) 가장 작은(nsamllest) 또는 가장 큰(nlargest) n개의 값을 구하고자 할 때 사용.
- df.sort_values(columns, ascending=True).head(n)와 동일한 결과.
- parameters
- n : int
- columns : list or str
keep : {‘first’, ‘last’, ‘all’}, default ‘first’
- first : 중복이 있는 경우, 가장 처음 나오는 값을 출력.
- last : 중복이 있는 경우, 가장 마지막에 나오는 값을 출력.
- all : 중복을 제거하지 않음. n개 이상의 결과가 나올 수 있음.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
df = pd.DataFrame({
'key' : ['A','B','C','D','E'],
'value' : [10,20,90,50,50]
})
df
# key value
# 0 A 10
# 1 B 20
# 2 C 90
# 3 D 50
# 4 E 50
df.nsmallest(3,'value',keep='all')
# key value
# 0 A 10
# 1 B 20
# 3 D 50
# 4 E 50
df.nlargest(3,'value')
# key value
# 2 C 90
# 3 D 50
# 4 E 50
explode
- def explode(column: Union[str, Tuple], ignore_index: bool=False)
- 예시) list의 값을 동일한 index로 풀고자 할 때 사용.
- parameters
- column : str or tuple.
- ignore_index : bool, default False. 만약 True라면, index를 순차적으로 부여함.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
d = {'A':[[1,2],'a',[],['a',1]],'B':list(range(1,5))}
df = pd.DataFrame(d)
df
# A B
# 0 [1, 2] 1
# 1 a 2
# 2 [] 3
# 3 [a, 1] 4
df.explode('A')
# A B
# 0 1 1
# 0 2 1
# 1 a 2
# 2 NaN 3
# 3 a 4
# 3 1 4
df.explode('A',ignore_index=True)
# A B
# 0 1 1
# 1 2 1
# 2 a 2
# 3 NaN 3
# 4 a 4
# 5 1 4