
Part 1.에 이어서 데이터 핸들링에 도움이 되는 python 함수들을 알아봅니다.
pivot
- def pivot(index=None, columns=None, values=None)
- 예시) index와 column에 대해 value를 가지는 형태로 변환할 때 사용 (pivot).
- index와 column에 대해 unique한 값을 가지고 있어야 함 (
pivot_table과의 차이). - parameters
- index : str or object or a list of str, optional
- columns : str or object or a list of str
- values : str, object or a list of the previous, optional
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import numpy as np
import pandas as pd
a = ['Apple','Banana']
A = list(np.repeat(a,3))
B = ['A','B','C']*2
C = list(range(1,7))
d = {'A':A,'B':B,'C':C}
df = pd.DataFrame(data=d)
df
# A B C
# 0 Apple A 1
# 1 Apple B 2
# 2 Apple C 3
# 3 Banana A 4
# 4 Banana B 5
# 5 Banana C 6
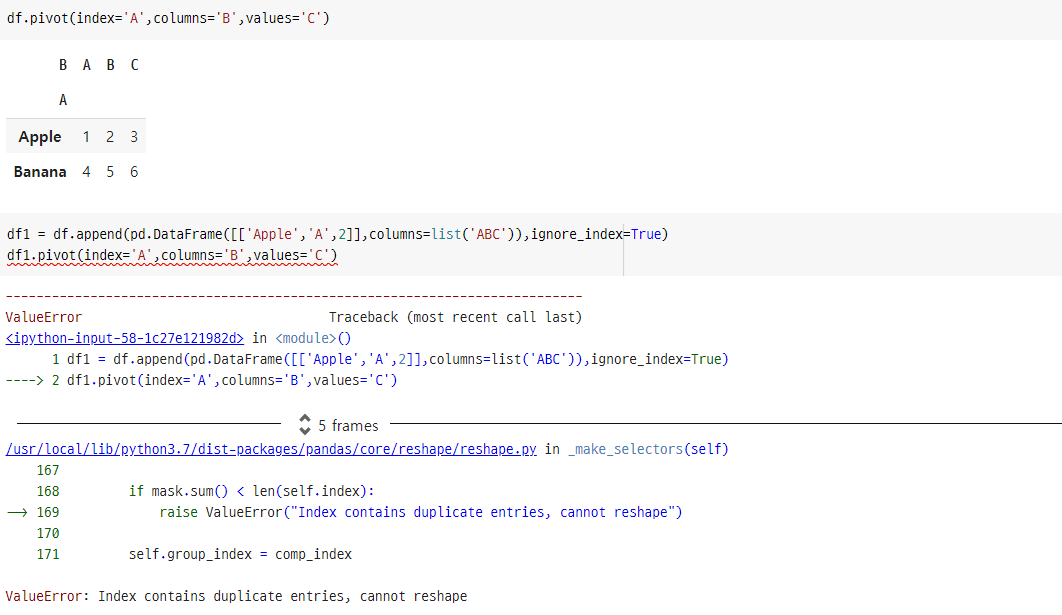
df.pivot(index='A',columns='B',values='C')
# index와 column에 대해 값이 unique하지 않으면 ValueError.
df1 = df.append(pd.DataFrame([['Apple','A',2]],columns=list('ABC')),ignore_index=True)
df1.pivot(index='A',columns='B',values='C')
pivot_table
- def pivot_table(values=None, index=None, columns=None, aggfunc=’mean’, …)
- parameters
- aggfunc : function, list of functions, dict, default numpy.mean
- fill_value : scalar, default None. aggregation 이후 missing 값에 대한 처리.
- margins : bool, default False
- margins_name : str, default ‘All’
1
2
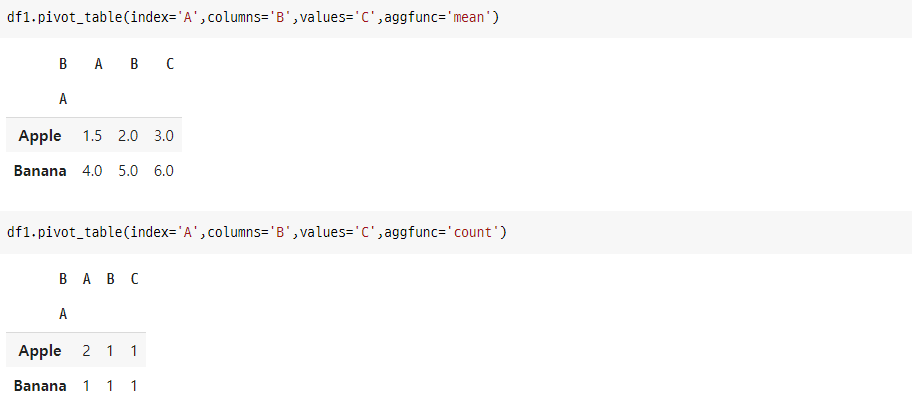
df1.pivot_table(index='A',columns='B',values='C',aggfunc='mean')
df1.pivot_table(index='A',columns='B',values='C',aggfunc='count')
groupby & agg
1
2
3
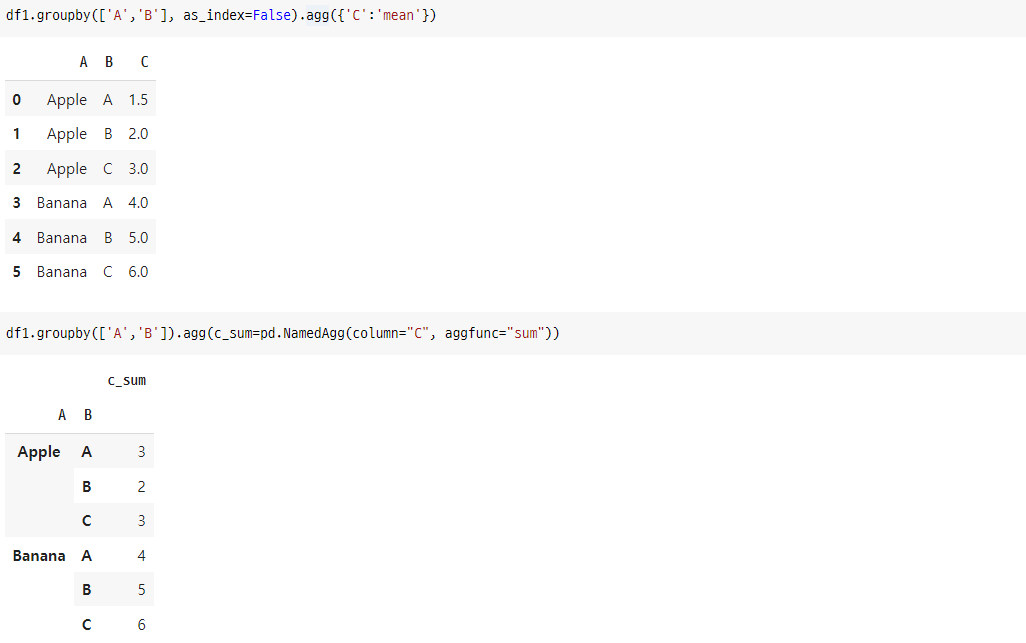
df1.groupby(['A','B'], as_index=False).agg({'C':'mean'})
df1.groupby(['A','B']).agg(c_sum=pd.NamedAgg(column="C", aggfunc="sum"))
1
2
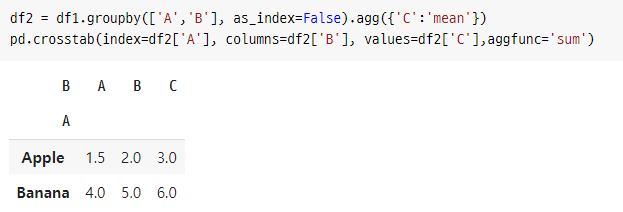
df2 = df1.groupby(['A','B'], as_index=False).agg({'C':'mean'})
pd.crosstab(index=df2['A'], columns=df2['B'], values=df2['C'],aggfunc='sum')
melt
- def melt(id_vars=None, value_vars=None, var_name=None, …)
- 예시) 데이터 format을 wide 형태에서 long 형태로 변환할 때 사용 (unpivot).
- parameters
- var_name : scalar
- value_name : scalar, default ‘value’
- col_level : int or str, optional. column이 MultiIndex일 때 사용.
1
2
3
4
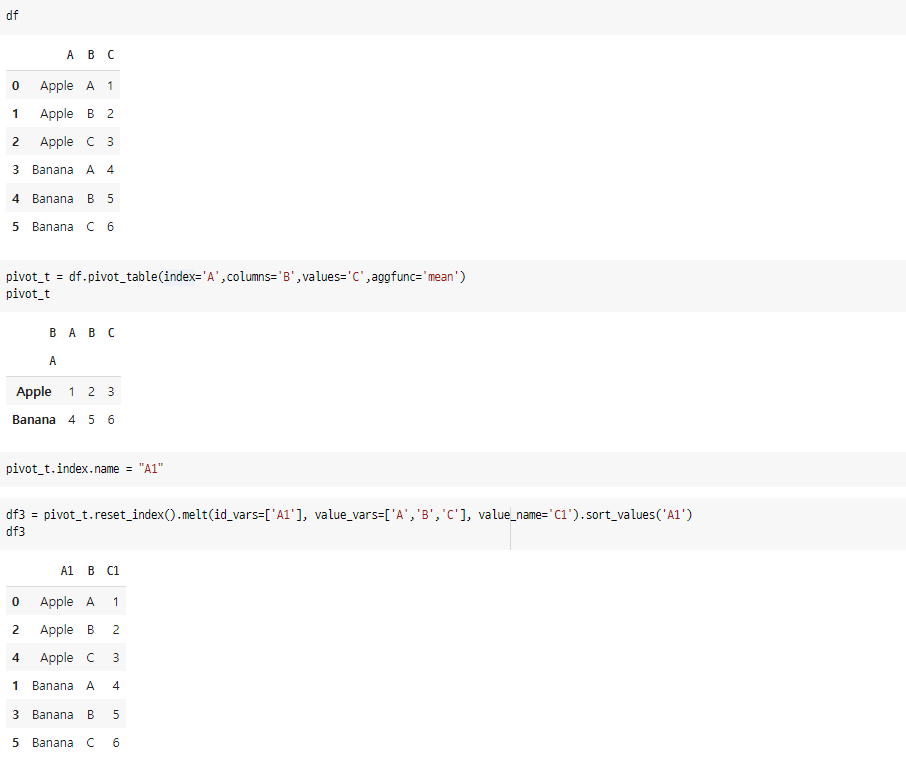
pivot_t = df.pivot_table(index='A',columns='B',values='C',aggfunc='mean')
pivot_t.index.name = "A1"
df3 = pivot_t.reset_index().melt(id_vars=['A1'], value_vars=['A','B','C'], value_name='C1').sort_values('A1')
df3
wide_to_long
- def wide_to_long(df: ‘DataFrame’, stubnames, i, j, …)
melt와의 차이 :wide_to_long함수는 column명이 ‘stubnames-suffix1’, ‘stubnames-suffix2’, … 와 같은 형태로 있어야 한다는 제약이 있음.- parameters
- df : DataFrame
- stubnames : str or list-like. wide 형태의 변수명 앞에 붙는 이름.
- i : str or list-like. id로 사용될 변수.
- j : str. suffix에 대한 이름.
- sep : str, default “”
1
2
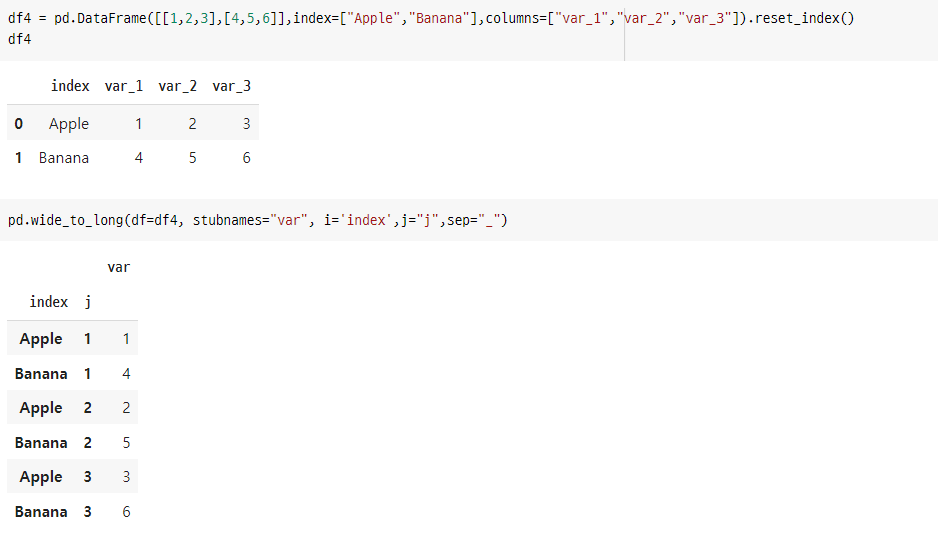
df4 = pd.DataFrame([[1,2,3],[4,5,6]],index=["Apple","Banana"],columns=["var_1","var_2","var_3"]).reset_index()
pd.wide_to_long(df=df4, stubnames="var", i='index',j="j",sep="_")
merge
- def merge(right, how=’inner’, on=None, left_on=None, right_on=None, …)
- parameters
- right : DataFrame or named Series
- how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
1
2
3
4
5
6
7
d1 = {'left_key':['A','B','C'],'value':[1,4,7]}
df1 = pd.DataFrame(d1)
d2 = {'right_key':['A','C','B'],'value':[2,8,14]}
df2 = pd.DataFrame(d2)
df1.merge(df2,left_on='left_key',right_on='right_key')

join
- def join(other, on=None, how=’left’, lsuffix=’’, rsuffix=’’, sort=False)
merge와의 차이 : index를 기본으로 하여 데이터를 결합하므로 사용함에 있어서 주의가 필요하다.parameters
- other : DataFrame, Series, or list of DataFrame
- on : str, list of str, or array-like, optional
- how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘left’
1
2
3
4
5
6
df1.join(other=df2, how='inner', lsuffix='_l', rsuffix='_r')
df3 = df1.set_index('left_key')
df4 = df2.set_index('right_key')
df3.join(other=df4,how='inner',lsuffix='_l', rsuffix='_r')
